 سلام دوستان.
سلام دوستان.
من شنیدم که الگوریتم فشرده سازی هافمن بهترین الگوریتم فشرده سازی هست و چیزی بین 20 تا 90 درصد فایل رو فشرده تر می کنه
طبق بررسی هایی که من انجام دادم زیاد بدرد فشرده سازی فایل نمیخوره و احتمالاً فقط برای فشرده کردن متن ها باشه.
راستی داداش علی ( hamishebahar ) اگه میشه سورس برنامه وین رر را به زبان C# برام بزارید .
راستش سورس وینرار رو من ندارم من فقط خود exe رو دیباگ میکردم که زیادم ازش سر در نیاوردم.
ولی احتمالاً بشه الگوریتمشو پیدا و پیاده سازی کرد.
انشالله بررسی میکنیم.
اگه هم بتونید برنامه ای که این کا را می کنه ( تبدبل برنامه کامپایل شده به سورس) را بزارید ممنون میشم
یه نرم افزاری هست به نام Reflector:
کد:
برای مشاهده محتوا ، لطفا وارد شوید یا ثبت نام کنید
کدگذاری هافمن:
درعلوم کامپیوتر و تئوری اطلاعات، کدگذاری هافمن یک الگوریتم کدگذاری برای فشردهسازی بیاتلاف اطلاعات است.
این تعبیر بر میگردد به استفاده از جدول کد طول متغیر برای کد کردن هر کدام از نشانههای مبدا (مانند کاراکترهای یک فایل). جدول کد طول متغیر از روشی بخصوص مبنی بر احتمال وقوع هر کدام از نشانهای مبدا بدست میآید. این روش بوسیلهٔ دیوید هافمن توسعه یافت. وی دانشجوی دورهٔ دکتری در رشتهٔ فلسفه در دانشگاه mit بود و در سال ۱۹۵۲ مقالهٔ «روشی برای تولید کدی با کمترین تکرار زوائد» را منتشر کرد.
در کد کذاری هافمن، از روشی خاص برای انتخاب نحوهٔ نمایش هر نماد استفاده میشود. روشی به نام کدهای بدون پیشوند(گاهی هم روش «کدهای پیشوندی» گفته میشود. یعنی در این روش رشتهای که نشان دهندهٔ یک کاراکتر خاص است هیچ گاه پیشوند رشتهٔ دیگر که نمایانگر کاراکتری دیگر است، نمیباشد.).در این روش کاراکترهای پرکاربرد تر با رشتههای بیتی کوتاهتری نسبت به آنهایی که کاربردشان کمتر است، نشان داده میشوند.
هافمن موفق شد کارآمد ترین روش فشرده سازی از این نوع را طراحی کند: نگاشت نکردن نشانهای منفرد مبدا به رشتههای بیتی یکتا، هرگاه تعداد تکرار نمادهای اصلی با آنهایی که برای ایجاد این کد مورد استفاده قرار گرفتند مطابقت کند، خروجیهایی با اندازهٔ کمتر تولید میکند. بعدها روشی برای انجام این کار پیدا شد که این کار را در زمانی خطی انجام میداد.
برای مجموعهای از نمادها با توزیع احتمالی یکنواخت و تعداد عضوهایی برابر با توانی از ۲، کد گذاری هافمن هم ارز با قطعه کد سادهٔ دوجملهای است. مانند کد گذاری ascii. کد گذاری هافمن روشی متداول برای ایجاد کدهای بدون پیشوند است بطوریکه عبارت «کد هافمن» به گستردگی به عنوان مترادفی برای «کد بدون پیشوند» استفاده میشود، هرچند چنین کدی با الگوریتم هافمن بدست نیامده باشد.
اگرچه کد گذاری هافمن برای کد کردن نماد به نماد بهینهاست، اما گاهی کارآمدی آن بیش از مقدار واقعی پنداشته میشود. برای مثال، کد کردن حسابی و کد کردن lzw، گاهی توانایی بالاتری در فشرده سازی دارند.
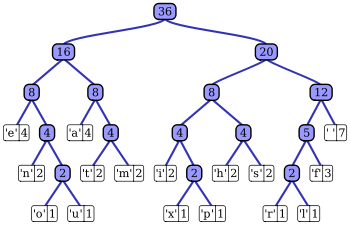

درخت هافمن، ايجاد شده از تعداد تكرار حرف هاي جمله ي «this is an example of a huffman tree».تعداد تكرارها و كد هر حرف، به همراه همان حرف در جدول زير آمدهاست. رمز كردن اين جمله به كمك اين كد، بدون در نظر گرفتن فاصلهها، به 135 بيت نياز دارد.
تاریخچه:
در سال ۱۹۵۱ David.A.Huffman و هم شاگردیهایش در کلاس «تئوری اطلاعات» دانشگاه MIT، حق انتخاب بین تحقیق در مورد یک مفهوم یا دادن امتحان پایانی را داشتند.استاد Robert M. Fano موضوع تحقیق را مسالهٔ پیدا کردن کارآمد ترین کد دودویی تعیین کرد. هافمن ناتوان در پیدا کردن کارآمد ترین، تصمیم گرفته بود خودش را برای امتحان پایانی آماده کندکه ایدهای به ذهنش رسید. ایدهٔ استفاده از درخت دودیی مرتب شده بر حسب تکرار(frequency) وتوانست اثبات کند که این کارآمد ترین روش است. در انجام این کار، شاگرد از استادش که با مبدع تئوری اطلاعات، Claude Shannon برای ساختن کدی مشابه کار کرده بود، پیشی گرفت. هافمن از مشکل اصلی روش کدگذاری نیم بهینهٔ Shannon-Fano coding جلوگیری کرده، درخت را به جای ساختن از بالا به پایین، از پایین به بالا ساخت.
تعریف مساله:
توضیح غیر رسمی
داریم: مجموعهای از نمادها و وزن هایشان (معمولا متناسب با احتمالها یشان)
پیدا کنید: کد دودویی بدون پیشوند، (مجموعهای از کدها) با کمترین امید ریاضی برای طول کد.(به طور معادل، درختی با کمترین مسیر وزن دار).
انواع :
انواع مختلفی از کد گذاری هافمن وجود دارد، که بعضی از آنها از الگوریتمهایی شبیه الگوریتم هافمن و بعضی دیگر از کدهای بهینهٔ پیشوندی (با محدودیتهای خاص برای خروجی)استفاه میکنند. در حالت اخیر، نیاز نیست که روش، شبیه روش هافمن باشد و حتی ممکن است زمان اجرایی چندجملهای هم نداشته باشد. لیست کاملی از مقالات مربوط به انواع مختلف کد گذاری هافمن، در «درختهای کد و تجزیه برای کد کردن بی زیان اطلاعات» [1] داده شدهاست.
کد هافمن n تایی
الگوریتم کد هافمن n تایی از الفبای {۰, ۱,..., n − ۱} برای کد کردن پیامها و ساختن درخت n تایی استفاده میکند. این روش دسترسی بوسیلهٔ هافمن و در مقاله اش بررسی شده بود.
کد هافمن انطباقی
نوع دیگری به نام کد هافمن انطباقی، احتمالاتی را که به صورت پویا و بر اساس تکرار واقعی در منبع اصلی است، محاسبه میکند. این به گونهای مربوط به خانوادهٔ الگوریتمهای LZ است.
الگوریتم الگوي هافمن
بیشتر اوقات، وزنهای مورد استفاده در اجرای کد هافمن، نمایانگر احتمالات عددی است ولی این الگوریتم چنین چیزی را نیاز ندارد بلکه فقط به راهی برای منظم کردن وزنها و اضافه کردن آنها نیازمند است. الگوریتم الگو هافمن امکان استفاده از هر نوع وزنی را میدهد.(ارزش-تکرار-جفت وزن ها-وزنهای غیر عددی) و هر کدام از روشهای ترکیبی مختلف. اینگونه الگوریتمها میتوانند مسائل فشرده سازی دیگر را نیز حل کنند.
كد هافمن با طول محدود
كد هافمن با طول محدود نوعي ديگر از كد هافمن است. اين نوع هنگامي مورد استفاده قرار مي گيرد كه هدف هنوز بدست آوردن طول مسير با كمترين وزن است اما يك شرط ديگر نيز وجود دارد و آن اين است كه اندازه ي هر كد، بايد كمتر از مقدار ثابت خاصي باشد. الگوريتم بسته بندي-ادغام اين مشكل را بوسيله ي يك الگوريتم حريصانه ساده شبيه به هماني كه در الگوريتم هافمن بكار رفته بود، حل مي كند. پيچيدگي زماني اين الگوريتم O(nL), كه L
هيچ الگوريتمي شناخته نشده كه اين كا را در زمان linear or linearithmic انجام دهد,بر خلاف مسائل پيش مرتب شده و مرتب نشده ي هافمن. ماكزيمم طول يك كدكلمه(codeword)است.
كد هافمن با ارزش حرفي متفاوت
در كد گذاري استاندارد هافمن، فرض شده است كه هر نماد در مجموعه اي كه كد ها از آن استخراج مي شوند،ارزشي يكسان با بقيه دارد: كد كلمه اي كه طول آن N است ارزشي برابر N خواهد داشت ،مهم نيس كه چند رقم آن 1 و چند رقم آن 0 است. وقتي با اين فرض كار مي كنيم، كم كردن هزينه ي كلي پيام ، با كم كردن تعداد رقم هاي كل 2 چيز يكسانند. كد هافمن با ارزش حرفي متفاوت به نحوي عموميت يافته كه اين فرض ديگر صحيح نيست: حروف الفباي كدگذاري ممكن است طول هاي غير همساني داشته باشند ، به خاطر خصوصيت هاي واسطه ي انتقال. مثالي بر اين ادعا،الفباي كد گذاري كد مورس است، كه در آن فرستادن يك 'خط تيره' بيشتر از فرستادن يك 'نقطه' طول مي كشد ، پس ارزش خط تيره در زمان انتقال بالاتر است. درست است كه هدف هنوز كم كردن ميانگين طول وزني كد است اما ديگر كم كردن تعداد نماد هاي بكار برده شده در پيام، به تنهايي كافي نيست. هيچ الگوريتمي شناخته نشده است كه اين را به همان روش و همان كارآيي كد قراردادي هافمن انجام دهد.
كد قانوني هافمن:
اگر وزن هاي مربوط به ورودي هاي مرتب شده بر اساس الفبا، به ترتيب عددي باشند، كد هافمن طولي برابر طول كد الفبايي بهينه دارد كه مي تواند از طريق محاسبه بدست آيد. كد بدست آمده از ورودي هاي مرتب شده از نظر عددي ، كد قانوني هافمن گفته مي شود و كدي است كه به خاطر سادگي رمز كردن و رمز گشايي ،در عمل استفاده مي شود. تكنيك پيدا كردن اين كد ، اكثرا كد گذاري Huffman-Shannon-Fano ناميده مي شود. و اين به خاطر آن است كه مانند كدگذاري هافمن بهينه، ولي در احتمال وزن ها مانند كد گذاريShannon-Fano coding الفبايي است. كد هافمن Shannon-Fano مربوط به اين مثال {000,001,01,10,11} است كه در آن طول كد كلمه ها ، همان مقداري است كه در حل اصلي آمده است.
نمونه پروژه ی#C:
 سی شارپ(#C) پروژه:
سی شارپ(#C) پروژه:
کد:
برای مشاهده محتوا ، لطفا وارد شوید یا ثبت نام کنید
با عرض پوزش از همه ی عزیزان و برنامه نویسان.احتمالاً تا آخر فروردین نیستم.gif "N Aggressive (17)") .
.





 جواب بصورت نقل قول
جواب بصورت نقل قول



.gif "N Aggressive (4)") که هم عجیبه که تا حالا چرا سر صدایی نکرده این قضیه، هم جالب و هم غیر قابل باور .. ولی به نکته ی جالبی اشاره کردن اونم بهم ریخت نظم بیت ها س مثلا میشه ملاک کار رو بیت های 0 قرار داد و اگه بیت های 0 در یک مجموعه (که میتونه 8 بیت یا بیشتر باشه ) کمتر از نصف بود مجموعه رو NOT کرد و با اینکار تعداد تکرار رو بالا برد و ... البته با افزایش حجم چون حالت ها خیلی بیشتر میشه تعداد احتمالات هم بالا میره و زمان به بینهایت میل میکنه که شاید به صرفه نباشه ولی غیر ممکن هم نیست .
که هم عجیبه که تا حالا چرا سر صدایی نکرده این قضیه، هم جالب و هم غیر قابل باور .. ولی به نکته ی جالبی اشاره کردن اونم بهم ریخت نظم بیت ها س مثلا میشه ملاک کار رو بیت های 0 قرار داد و اگه بیت های 0 در یک مجموعه (که میتونه 8 بیت یا بیشتر باشه ) کمتر از نصف بود مجموعه رو NOT کرد و با اینکار تعداد تکرار رو بالا برد و ... البته با افزایش حجم چون حالت ها خیلی بیشتر میشه تعداد احتمالات هم بالا میره و زمان به بینهایت میل میکنه که شاید به صرفه نباشه ولی غیر ممکن هم نیست .

.gif "N Aggressive (38)") ) .. شاید با روشی بشه مکان این بیت ها رو هم مشخص کرد که کمتر از 8 بیت فضا اشغال کنه
) .. شاید با روشی بشه مکان این بیت ها رو هم مشخص کرد که کمتر از 8 بیت فضا اشغال کنه.gif "N Aggressive (19)") )
)